Core Concepts
Let’s dive deep into the internals of Turbopack to figure out why it’s so fast.
The Turbo engine
Turbopack is so fast because it’s built on a reusable library for Rust which enables incremental computation known as the Turbo engine. Here’s how it works:
Function-level caching
In a Turbo engine-powered program, you can mark certain functions as ‘to be remembered’. When these functions are called, the Turbo engine will remember what they were called with, and what they returned. It’ll then save it in an in-memory cache.
Here’s a simplified example of what this might look like in a bundler:
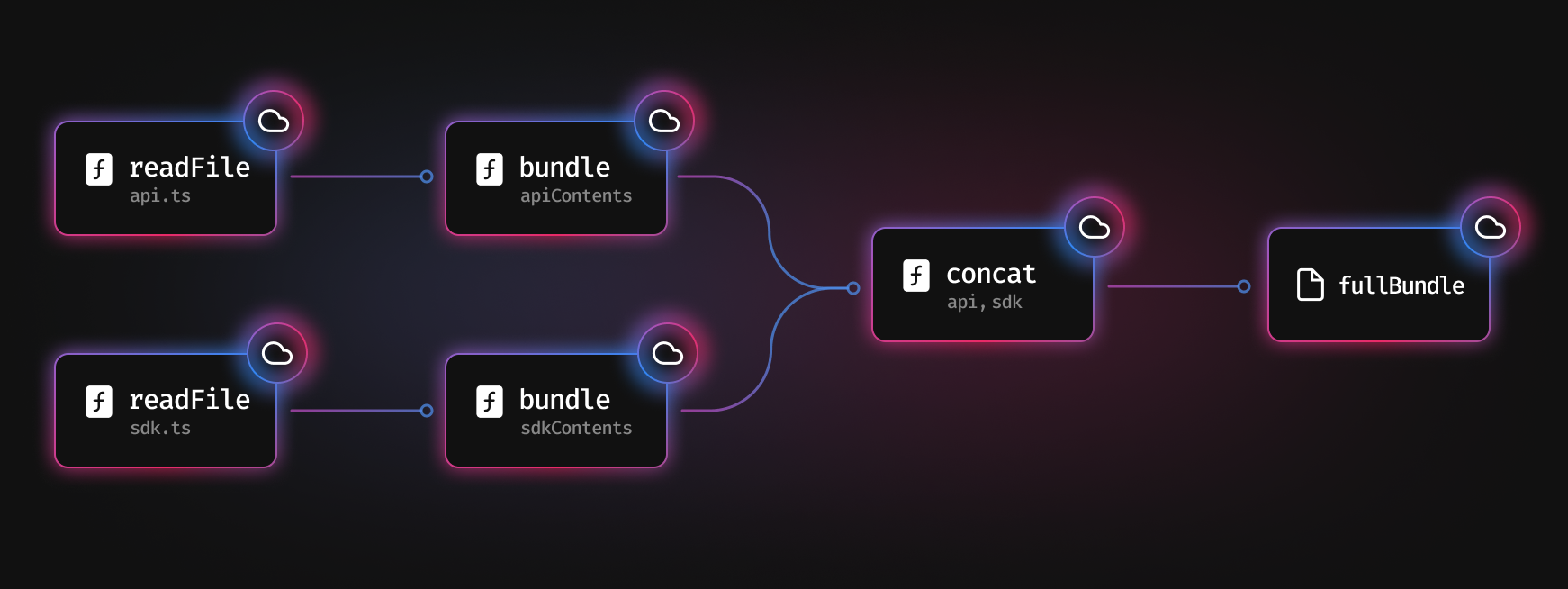
We start with calling readFile on two files, api.ts and sdk.ts. We then bundle those files, concat them together, and end up with the fullBundle at the end. The results of all of those function calls get saved in the cache for later.
Let’s imagine that we’re running on a dev server. You save the sdk.ts file on your machine. Turbopack receives the file system event, and knows it needs to recompute readFile("sdk.ts"):
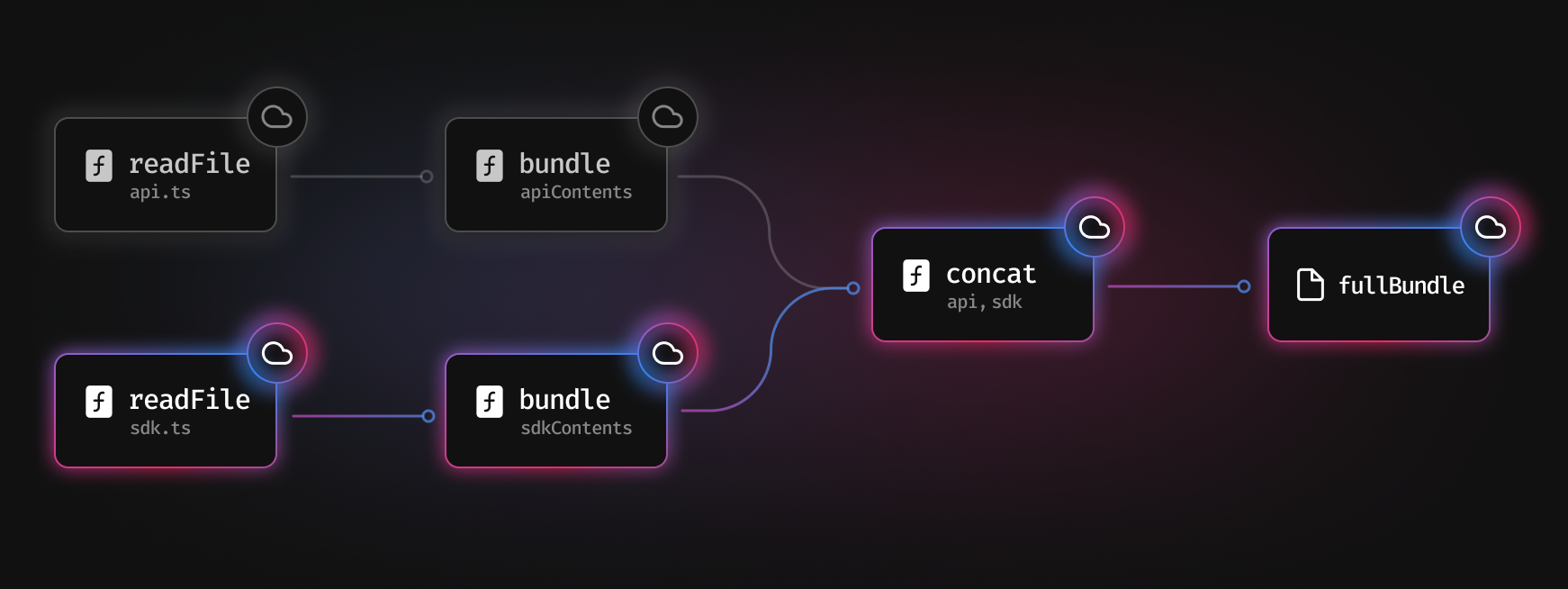
Since the result of sdk.ts has changed, we need to bundle it again, which then needs to be concatenated again.
Crucially, api.ts hasn’t changed. We read its result from the cache and pass that to concat instead. So we save time by not reading it and re-bundling it again.
Now imagine this in a real bundler, with thousands of files to read and transformations to execute. The mental model is the same. You can save enormous amounts of work by remembering the result of function calls and not re-doing work that’s been done before.
The cache
The Turbo engine currently stores its cache in memory. This means the cache will last as long as the process running it - which works well for a dev server. When you run next dev --turbo in Next.js 13+, you’ll start a cache with the Turbo engine. When you cancel your dev server, the cache gets cleared.
In the future, we’re planning to persist this cache - either to the filesystem, or to a remote cache like Turborepo’s. This will mean that Turbopack could remember work done across runs and machines.
How does it help?
This approach makes Turbopack extremely fast at computing incremental updates to your apps. This optimizes Turbopack for handling updates in development, meaning your dev server will always respond snappily to changes.
In the future, a persistent cache will open the door to much faster production builds. By remembering work done across runs, new production builds could only rebuild changed files - potentially leading to enormous time savings.
Compiling by Request
The Turbo engine helps provide extremely fast updates on your dev server, but there’s another important metric to consider - startup time. The faster your dev server can start running, the faster you can get to work.
There are two ways to make a process faster - work faster, or do less work. For starting up a dev server, the way to do less work is to compile only the code that’s needed to get started.
Page-level compilation
Versions of Next.js from 2-3 years ago used to compile the entire application before showing your dev server. In Next.js 11 (opens in a new tab), we began compiling only the code on the page you requested.
That’s better, but it’s not perfect. When you navigate to /users, we’ll bundle all the client and server modules, dynamic-imported modules, and referenced CSS and images. That means if a large part of your page is hidden from view, or hidden behind tabs, we’ll still compile it anyway.
Request-level compilation
Turbopack is smart enough to compile only the code you request. That means if a browser requests HTML, we compile only the HTML - not anything that is referenced by the HTML.
If a browser wants some CSS, we’ll compile only that - without compiling referenced images. Got a big charting library behind next/dynamic? Doesn’t compile it until the tab showing the chart is shown. Turbopack even knows to not compile source maps unless your Chrome DevTools are open.
If we were to use native ESM, we’d get similar behavior. Except that Native ESM produces a lot of requests to the server, as discussed in our Why Turbopack section. With request-level compilation, we get to both reduce the number of requests and use native speed to compile them. As you can see in our benchmarks, this provides significant performance improvements.